Alder Lake Interconnect Bandwidth

If you can recall earlier in the article I spoke about how Intel claimed that Alder Lake-S would support up to 1000 GB\s or 1TBs of bandwidth within the microarchitecture. Well I wanted to know how much bandwidth I could get with my Alder Lake-S CPU and DDR5-4800Mhz running default settings. DDR5-4800Mhz is the official supported DDR RAM frequency, but of course Alder Lake is capable of handling much higher DRAM frequencies. I ran a lot of low-level benchmarks on Alder Lake in relation to the DDR5-4800MT\s and I was surprised from what I learned. However, the architecture is brand new and I am seeing all types of performance numbers. Some of the software I use doesn’t know what to do with the CPU and I am trying to look past all of the bad data since its already hard enough to benchmark a micro-architecture as it is. The results below will use various workload scenarios to determine the ending results. With all of that being said we will take a look at all cores (P & E Cores) and see how much performance I can get when all 16 Cores & 24 Threads work together.
Performance & Efficient Cores
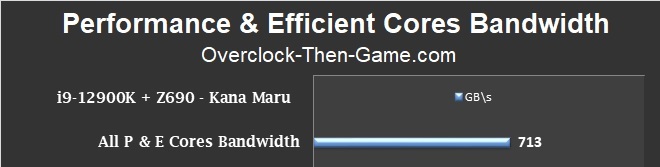
I was able to pull 713GB\s of total bandwidth in my test. That’s fairly close to 1000 GB\s, but we must remember that the 1000GB\s (1 TB\s) bandwidth that Intel claimed isn’t all dedicated to the cores so I consider this a fair number. Another thing to consider and one you might want to refer back to is the latency chart on the previous page. Latency plays a big part in bandwidth performance and the result above is an aggregate of different workloads. If you recall the E-cores can have massive spikes in latency and the further the cores are away from each doesn’t help matters either.
Performance Cores Bandwidth (8 P-Cores)
Now that we have seen how well the P & E Cores work together let’s see how well they work separately. We will start with the Performance Cores and see how much Bandwidth I can achieve with them working together without the Efficient Cores.
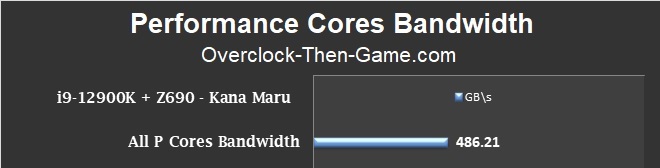
The Performance Cores were able to pull 486 GB\s on average. However, I recorded the top bandwidth performance maxing at an incredible 1.72 TB\s (Terabytes)! Obviously the 1.72 TB\s and 1.35 TB\s I recorded would be under the absolute best scenario which is why I prefer to use many different workloads to aggregate the typical performance. We will visit the best case scenarios and maximum performance for Alder Lake P and E Cores later in this article. One thing I noticed is that the Intel Thread Director and Intel’s Turbo Max is very aggressive with the low-power modes. Although I explained this earlier in the article I would like to repeat that the Alder Lake-S CPU runs DDR5 in “Gear 2” by default (DDR4 = Gear 1). So that means my LLC clock is only at 3600Mhz for the majority of all benchmarks thus far according to my monitoring software. Occasionally it would jump to 4700Mhz, but quickly drop back down to 3600Mhz. So it is possible that I will be able to gain more performance as I begin to overclock the CPU.

Efficient Cores Bandwidth (8 E-Cores)
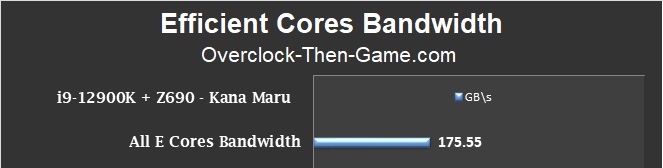
In this benchmark I attempted to determine how much performance I could get from both clusters containing only the Efficient Cores (x2 Clusters = 8 E-Cores). Although the Efficient Cores individually are capable of some serious bandwidth performance, as we will see shortly in this article, the latency amongst the E-Cores clusters shown earlier should be taken into consideration as that will affect bandwidth. However, with each individual E-Core they have quick access to the L2 Cache, L3 Cache and DRAM based on my testing. The best performance BW I recorded was 413.43 GB\s. The average was 176GB\s so it’s safe to say that the E-Cores are well equipped to handle various workloads.
One Efficient Cluster Bandwidth (4 E-Cores)
In the previous benchmark we saw both Efficient Clusters (8-cores) working together. Now I would like to take a look at how well each Cluster works independently (4-Cores). This should show the “best case” scenario since only 4 Efficient Cores will work on the same workload and not have to worry about the long cycles and\or latency to the second Efficient Cluster (or the Performance Cores).

This benchmark shows how efficient both Clusters can be if they are working on separate workloads. As long as the Efficient Clusters doesn’t need to share data between each other, or limited sharing, we see that it is possible to accomplish roughly 307 GB\s. That would make the Efficient Clusters (at 307GB\s) about 54% slower than the Performance Cores. When the Efficient Cores were working on the same workloads we saw the performance drop to only 176GB\s earlier, but each Cluster performed very well when separated. This could simply be a software limitation to the new Intel Hybrid Architecture. I will continue to monitor this behavior, but I thought I would share my results. If Intel and Microsoft can ensure that specific workloads can stay within a certain cluster then they would avoid the high latency issue which affects bandwidth. This would allow the separate Efficient Clusters and the Performance Cores to theoretically output around 782 GB\s when working on separate workload threads. This would make the Efficient Cores extremely efficient even at stock settings. In the absolute best case scenario the bandwidth max was 389 GB\s on Efficient Cluster #1 and 387 GB\s for Efficient Cluster #2.
All Performance and Efficient Core Results

This chart will give a clearer picture to the differences between the P & E Cores. We can see the difference between the core segments (P and E) and how well they work together. So although I did hit 713 GB\s with all cores working together as I stated earlier Intel didn’t state that the total 1000 GB\s interconnect speed wasn’t solely dedicated to only the P and E Cores. There are a ton of other features and hardware that needs access to the micro-architecture interconnects paths. However, if Intel and Microsoft’s Windows 11 scheduler can ensure that the Efficient Clusters (4 E-Cores) can handle workloads without sending or receiving data to the other Efficient Cluster then we could see the bandwidth increase to 782 GB\s instead of 713 GB\s.