Alder Lake Interconnect

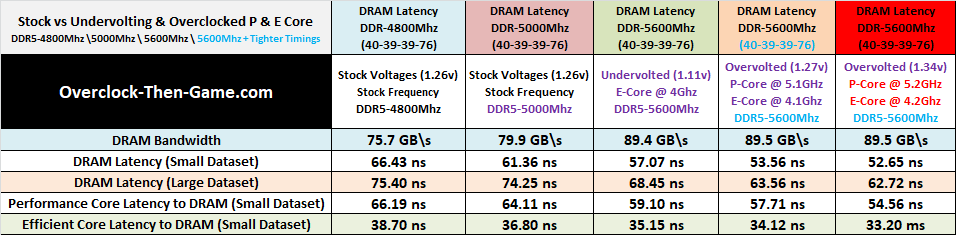
Not much has changed since my last benchmarks (P: 5.1GHz \ E: 4.1GHz) as expected. However, any increase is good in my book. I will be comparing the stock and overclock settings while showing all of my results thus far. Starting with the DRAM Bandwidth I have increased my bandwidth from 75.7 GB\s (DDR5-4800Mhz) to 89.5GB \s (DDR5-5600Mhz) which is an 18.22% increase. DRAM Latency (Small dataset) now shows the latency decrease from (stock) 66.43 ns to 52.65 ns. This is a 23% difference in latency. When it comes to latency lower is better. My DRAM Latency (Large dataset) shows a decrease of 12.68 ns. This makes the stock results 20% slower than my overclock results. Getting the large datasets down to 62.72 ns is great and hopefully I can continue to push the DRAM frequencies further. I have combined the average of all the P-Cores and E-Cores in their respective columns instead of listing each core individually. The Performance Cores shows a decrease of 18% when compared to the stock settings. The Efficient Cores shows a decrease of 15%. The Efficient Cores have always shown great low-latency to DRAM and could lead to some great performance results in future micro-architectures from Intel.
Performance & Efficient Cores
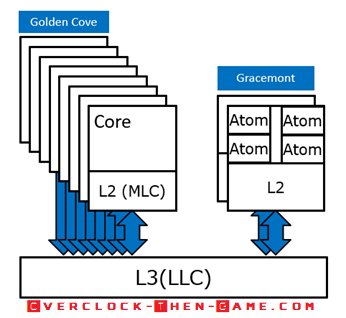
Now that we have seen how much quicker the Intel 12th Generation processor can access and retire data we can now begin to see how those latency decreases apply to actual workloads and benchmarks. Similar to my initial Alder Lake review I will be taking another deep-dive into the micro-architecture. Below we will take a look at the actual performance increases from the “Golden Cove” Performance Cores and “Gracemont” Efficient Cores. There are 8’ Golden Cove’ cores and 8 ‘Gracemont' Cores. The 8 ‘Gracemont’ Efficient Cores are clustered in pairs. So one Efficient Cluster contains only 4 ‘Gracemont’ Efficient Cores and those 4 Efficient Cores share the same L2 Cache. The Efficient Cores are also officially known as 'Atom' Cores. I will be comparing each Cluster individually and I will be comparing both Clusters working together on various workloads. This way we can see exactly how much my overclocks have increased with each Cluster and we will also be able to see how well the Cluster works when it doesn’t need to send data to and from the Performance Cores or the adjacent Cluster. Meaning that latency won’t affect performance as much since the Cluster won’t need to send or wait for other cores (caches and so on) within the micro-architecture.

I will start with all of the cores working together on various workloads to show the overall performance increase. The stock frequency under a full CPU load is P: 4.9GHz \ E: 3.7GHz, Ring: 3.7GHz & DDR5-4800Mhz. My overclock results are P: 5.2GHz (+300) \ E: 4.2GHz (+500), Ring: 4.0GHz (+300) & DDR5-5600Mhz (+800). I have increased my overall performance by 67GB\s pushing my previous result of 713 GB\s up to 780 GB\s. That represents an 8% increase in performance and while 8% might not seem like a lot to most people, here we can see that it translates to 67 GB\s. Alder Lake was already capable of handling workloads with no problems, but an extra 67GB\s is very nice.
Performance Cores Bandwidth (8 P-Cores)

Now just focusing only on 8 Performance Cores we see an increase of 40 GB\s. I was able to increase my performance by 8.3% and my when working together all 8 Performance Cores were capable is moving 526.49 GB\s.
Efficient Cores Bandwidth (8 E-Cores)

Now we will turn our attention to the overclocked Efficient Cores. With all 8 E-Cores working together I have increased my results by 11%. This is an additional 19.2 GB\s.
Single Efficient Cluster Bandwidth (4 E-Cores)

This chart shows each Efficient Core individually. My overclock results show that both Clusters now perform the same. Cluster #1 (x4 E-Cores) performance increased by 9 GB\s. Cluster #2 (x4 E-Cores) performance increased by 12 GB\s. Cluster #2 received the most significant performance increase since it now matches Cluster #1.