Analyzing Futuremark Time Spy Benchmark

DirectX 12 has been the talk across the web for years and a lot of people have been waiting for Futuremark to update 3Dmark with a DX12 API. Last year we got a glimpse of the benchmark running and now we can finally get our hands on it and benchmark for countless hours. Time Spy is basically the same as older benchmarks from Futuremark except there is no “Combined Score” test. DX12 is the future and the future is here. There have been some issues surrounding the Time Spy benchmark.
There has also been a lot of misinformation passed around the net as usual. This time it is regarding DX12, preemption, concurrency and Asynchronous Compute. There are some people who know what they are talking about, but at the end of the day we all make mistakes and live & learn. Regarding DX12 and AMD Asynchronous Compute, it’s pretty straight forward or so we think. Just know that DX12 & Vulkan allows developers to get more out the hardware using concurrency. There are many forms of concurrency. This isn’t a tutorial so I won’t be preaching and teaching programming, although I know a few languages, and I also won’t go deep in the software that I use either. Over the next couple of years we will see which developers can adapt to modern APIs and who cannot.
What Is The Issue And What IS Asynchronous Compute?
Well there are two issues. One issue being that people are upset that Advanced Edition purchasers have to pay more money for the Time Spy “advanced” features. The other issue, the issue I care about the most, is the DX12 benchmark not properly supporting Asynchronous Compute. Asynchronous Compute has been the most popular buzz word since late 2014 – early 2015 and now in 2016 it’s basically something that some people know nothing about apparently. Asynchronous Compute is a term from AMD that they have been using for many years and by that I mean as early as 2011.
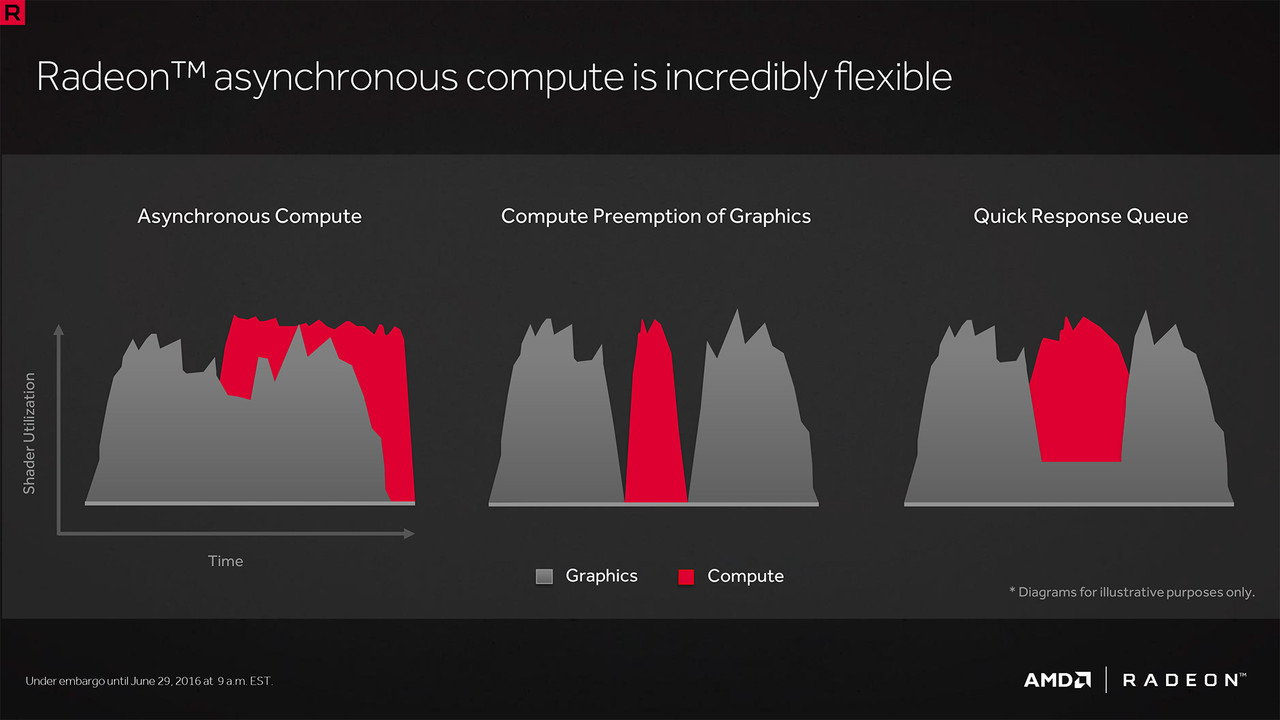
As usual, AMD was thinking about the future and pushing technology further. AMD still had two battles happening at the same time, Nvidia and Intel. Nvidia was the go to brand and although AMD\ATI had good hardware, Nvidia was just the more popular brand. The GTX 460 was still getting tons of praise and Sandy Bridge wasn’t going to make AMD feel any better. AMD created a new architecture back then named GCN [Graphics Core Next]. GCN contained something named “Asynchronous Compute Engine” or ACE. Dropping their old VLIW4 for GCN allowed AMD to simplify their architecture and hopefully scale their architecture in the future. There are multiple ACEs in the GCN architecture depending on the generation and model# on your GPU. ACEs allow the architecture to work in parallel as well as independent from one another while handling compute queues. There are many other features, but I won’t go deep into the architecture.
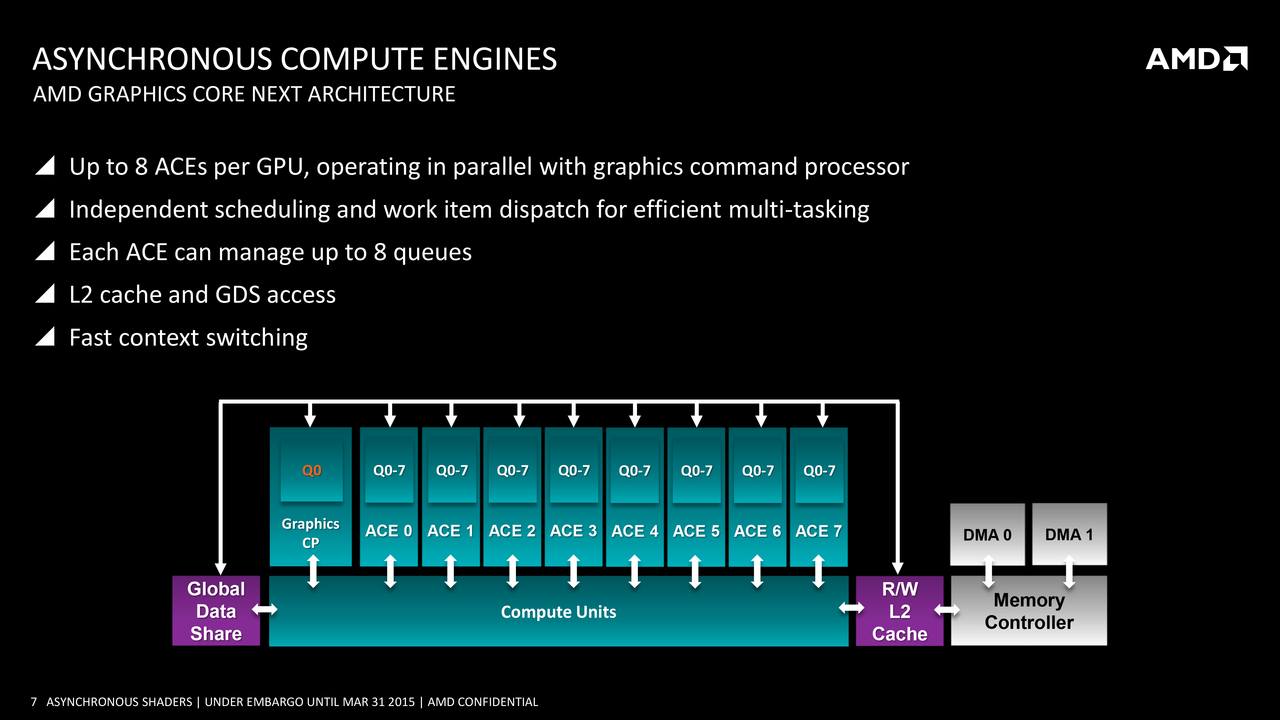
So the term “Asynchronous Compute” is an AMD thing or at least it was. However, now Asynchronous Compute is used outside of the GCN architecture. Modern APIs can now take advantage of the GCN architecture to get the most out of the hardware. That means that developers can no longer depend on drivers to take care of some things or continue to program sequentially. Well developers can program like they did for older APIs such as DX11\10\9 and OpenGL, but they will be defeating the purposes of the modern API and modern hardware. Console developers are already enjoying GCN and Async Compute .Now that we have covered some of the Async Compute background let’s look more into the issues surrounding the Time Spy DX12 benchmark.
If Your CPU Is Overclocked Time Spy Doesn’t Care
Unlike any other benchmark to date and also unlike any other DX12 benchmark Ive tested, Time Spy doesn’t seem to care whether your CPU is overclocked or running stock settings. The Graphics Score will nearly be the same regardless. In other words the DX12 and Vulkan games that I have reviewed such as Rise of the Tomb Raider, Hitmanand Doom, all of those games benefit from the CPU sending more data to the GPU. Even older 3DMark benchmarks increased the Graphic Score when overclocking the CPU, but this isnt the case in DX12 with Time Spy. We can expect most modern gaming engines to scale across all cores with DX12 and Vulkan, well that is if the engines are programmed correctly. Now if you decide to overclock your GPU you can expect a decent bump, but with DX12 and Vulkan, usually overclocking the CPU will increase your performance. So don’t expect anything from overclocking the CPU in Time Spy. It will not affect the GPU Graphics Score or send more data to the GPU. Apparently this benchmark has a preset workload of data to send. In other words this benchmark does not represent how DX12 and Vulkan is used in actual games.
Here are my Graphics Score results while a running stock and overclocked CPU settings.
| Stock CPU + Stock Fury X | 4Ghz CPU + Stock Fury X |
4.6Ghz CPU + Stock Fury X |
| Graphics Score: 5068 | Graphics Score: 5078 | Graphics Score: 5076 |
Some users running multiple AMD GPUs have stated that they are experiencing stutter issues and issues that were similar to DX11 FireStrike. DX11 was limited and AMD did have significantly higher overhead issues, but this shouldn’t be the case with DX12 and\or Vulkan.
Futuremarks One Shoe Fits All Approach
So it appears that Time Spy does not send enough data to the GCN architecture. From what I can see the GPU is starving for more work and there’s some weird behavior going on. I’ve been looking at a lot of data and comparing my findings to games like Doom while running the Vulkan API and Hitman while running the DX12 API. Time Spy doesn’t appear to send to as much data as possible to the GPU. It appears to send a specific amount of data in a preset fashion as I suggested above. For instance, at times there are workloads that appears to be sending some parallel workloads to the AMD GPU, but other times the data is held off and sent in a sequential manner. This behavior is NOT found in other DX12 or Vulkan games. Time Spy also appears to send smaller amounts of workload to the GPU. I looked at two different Time Spy benchmark runs to ensure that I was getting the full picture. Throughout the benchmarks the workload definitely switches to a sequential workflow in every test. This is not very helpful for the GCN architecture and is not full use of DX12 async compute. Instead of uploading the data which can eat up to or more than 20GBs of RAM and take many people quite sometime to download, Ill post a quick comparison screen shot of Time Spy and Doom Vulkan.
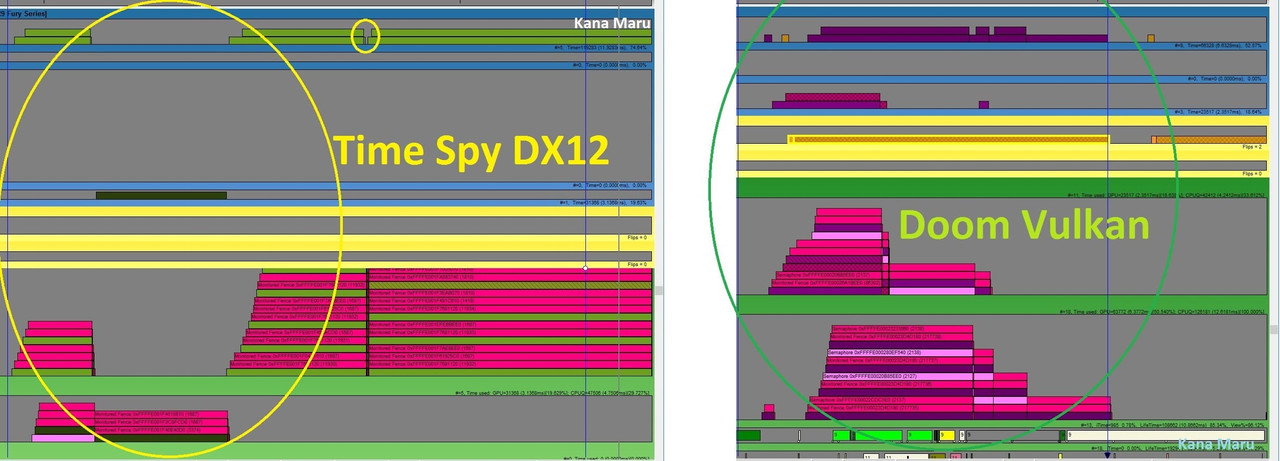
The chart above shows why one data path will not be sufficient for comparing Geforce GPUs against Radeons GPUs. On the left you can clearly see that the Time Spy DX12 benchmark is sending data in a DX11 manner, sequentially. On the right you can also clearly see that Doom is sending the data concurrently. The GPU is constantly working while running Doom as well. There are no gaps in performance and the GPU is working concurrently and in parallel on the Doom chart. The CPU is also constantly feeding data and the GPU is never running out of data to execute. This isnt the case with Time Spy. Time Spy doesnt send data right away like Doom does for the hardware to take care of. Time Spy makes my Fury X wait for data. Also the data that is sent from Time Spy is processed so fast that the GPU has idle periods. These idle periods are not found in Doom while running the Vulkan API.
Im not sure what is going on with Time Spy, but it definitely is not sending enough data. It is doing something, but nothing productive. Time Spy doesnt make efficient use of parallel workloads or CPU cores. As I stated earlier, Im not sure what the Time Spy benchmark is queuing up, but it definitely NOT work for the GPU. This behavior is happening on purpose since it I have duplicated my results and went through a lot of captured data. Doom sends plenty of data and Time Spy sends smaller chunks of data. Sometimes the data is so small its causing the GPU to simply wait which hurts performance.
I also checked out Hitman performance and Hitman has a lot going on. The good news is that Hitman DX12 doesnt starve the GPU. Hitman DX12 sends plenty of data and keeps the GPU busy just like Doom+Vulkan. Himan also has some really good efficient use of concurrency. I think its possible for Id Software to get more performance out of Doom with Vulkan as well based on what Ive seen in Hitman. Time Spy seems to have areas throughout the benchmark where the GPU is caught starving for data or is fed data in a sequential fashion. This shouldnt be the case for true asynchronous compute in DX12. This is not a good look and its apparent that Time Spy should not be used to directly compare Radeon and Geforce performance. However, Im sure that reviewers will add the results on charts anyways.
So Time Spy appears to take a "one shoe fits all" approach to benchmark multiple GPUs from different manufacturers. This way of programming is unacceptable since Nvidia definition of Async Compute is not the same as AMDs original definition of Async Compute. In other words, Futuremark needs to program a path for Nvidia hardware and AMD hardware separately. It’s impossible for both of them to use the same path since one will suffer more than the other. This is also an issue because websites, YouTube Personalities and reviewers will be using this benchmark to compare the Geforce GPUs against the Radeon GPUs. The performance will be misleading to readers and people who do not understand everything that is going on behind the scenes. Perhaps the Time Spy developers see this differently.
Revisiting The Term "Asynchronous Compute"
Now Nvidia has been claiming that they support Async Compute since Maxwell. Several developers have spoken out and told everyone countless times that Nvidia GPUs cannot support Async Compute, but that isn’t stopping Nvidia from having presentations on their “Enhanced Async Compute” with Pascal. So basically Nvidia created and actually showed “Enhanced Async Compute” while using DX11. As hilarious as that may sound, Nvidia is serious. They still have GPUs to sell and they must stay competitive, even if they have a large share of the market already.
Nvidia “Enhanced Async Compute” is basically a newer and better form of preemption. The issue with preemption is that it is not asynchronous so therefore it cannot be async compute. Preemption is not parallel at all and can cause overhead issues. Preemption basically causes data to stop for more important or higher priority data that must make it to the GPU immediately. This still causes delays and stops the flow of data to the GPU. So you will end up with the GPU waiting for important data and waiting again for normal data. Context switches must occur and this only cause more overhead issues, this is what DX12 and Vulkan is attempting to remove. There are number of ways you can handle preemption, but it’s never going to be truly asynchronous. Pascal also adds Dynamic Load Balancing which helps. Nvidia has also added graphics preemption at the pixel level and compute preemption at the thread level. At the end of the day it’s basically time slicing which will occur a bit of overhead regardless. So in my opinion and as I stated in an earlier GTX 1080 article, Nvidia’s answer to DX12 is brute force. By brute force I mean higher core clocks instead of putting money into the R&D to improve their architecture.
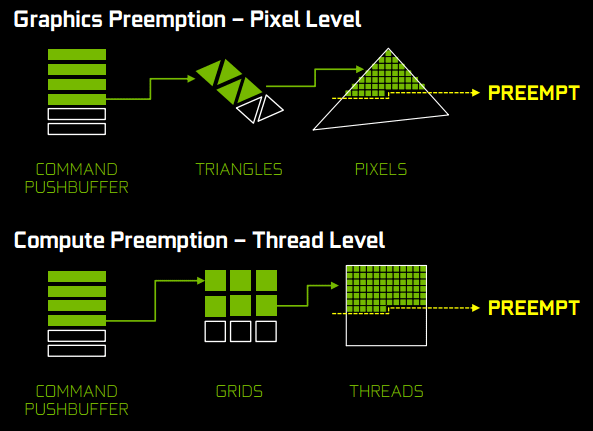
So this means that developers will have to create a rendering path for Nvidia and AMD. If developers write code that is parallel and contains a lot of data Nvidia GPUs might not be able to handle the data, where else AMD might have no issue handling the data. On the other hand if you don’t send enough data to the GPU, Nvidia will be able to maximize their GPU performance, but the AMD GPU will be starved for more work. This is where we are now with “async compute” from both companies. AMD intentions were never to destroy Nvidia users or Nvidia by giving Mantle to Microsoft [DX12] and Khronos [Vulkan]. As far as I know AMD has stated that they just want to make sure that gamers get more performance regardless of if they are running Nvidia or AMD hardware. I remember this statement because I was actually running two Nvidia GTX GPUs in SLI at the time. So preemption is still possible, but you will not get the most benefit out of the APIs by using preemption.
Conclusion
Time Spy does not and cannot show the true performance for both Geforce and Radeon GPUs. Theres only one true definition for "Asynchronous Compute", but now Nvidia has their "Enhanced Asynchronous Compute" floating around to muddy water even more. So now developers are faced with an issue, program with preemption in mind or ensure that the GPU is constantly fed with workloads. 3Dmark has always been used to compare AMD and Nvidia GPUs and this is unlikely to change. It would be nice if Futuremark would create two paths, but apparently they will not since AMD and Nvidia signed off the current release. Which is 100% fine if you understand not to compare the different architectures. Luckily we have plenty of DX12 & Vulkan titles on the market with plenty more to come this year and next year. Im hoping more developers focus on Vulkan since it can be used on more platforms. I wrote this article just to let you guys and gals know what I was experiencing. DX12 & 1440p is usually not an issue in DX12, but now I can see why my performance is so low while running the Time Spy benchmark.
Thank you for reading, feel free to leave a comment below.